 Reddit SEO
Reddit SEO
 WooCommerce
WooCommerce
 Shopify
Shopify
 Magento
Magento
 BigCommerce
BigCommerce
 Neto
Neto
 Headless
Headless
 ChatGPT
ChatGPT
 Gemini
Gemini
Having duplicate content on your website sometimes can be unavoidable due to several reasons and we all know Google doesn’t like that.
Wondering how to avoid this issue and keep Google happy? Let’s introduce you to something known as a canonical tag to help you solve duplicate content issues quickly and easily.
We know this can be somewhat of a technical topic/concept for many new people starting out in the SEO world but like always we here to simplify things.
In this beginner’s guide, you will learn:
- What is a canonical tag?
- What does a canonical tag look like?
- Relationship Between canonical tag & SEO
- When should you use a canonical tag?
- Common mistakes to avoid when implementing canonical tags
- How to implement canonical tags on Your Website?
Read on to see how to make the best use of the canonical tag on your website.
What Is a Canonical Tag?
A canonical tag is an HTML link element that is designed to tell search engines that a specific URL represents the master copy amongst a set of duplicate pages. In other words, you are specifying to Google the ‘preferred’ page or the original source you want it to focus on and rank.
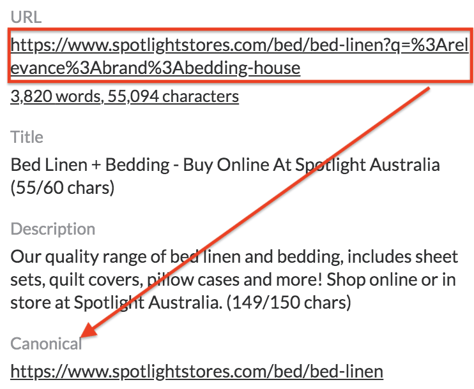
Duplicate content can arise easily, especially with big websites that offer a product in a range of colours, variants, or sizes. Below is an example from Spotlight. If you head over to their Bed Linen page and filter your choice by ‘bedding house’ under ‘brand’ the below URL string will be generated.
This will be the same case across any variation or facet a user decides to filter their search by (e.g. brand, thread, price) where a random URL string will be generated.
To avoid having these URL strings indexed and crawled by Google, Spotlight has canonicalised it back to the original source. This indicates to Google that this is the ‘preferred’ URL or the master copy (https://www.spotlightstores.com/bed/bed-linen) amongst a set of URLs that may appear to be the same.
If you’re wondering what tool helps with identifying this, it’s SEO Minion. A free chrome extension (thank us later!)
According to Google, it’s important to note that canonical URLs can sometimes be ignored as Google might choose to focus its efforts on a different page than the canonical page you set up, for various reasons.
A canonical URL is only a hint, not a directive that Google will respect all the time.
History Behind the Canonical Tag
To avoid confusion, the three main search engines banded together in 2009 to make things clearer for everyone.
Web developers could now add a new HTML attribute value within the existing tag. They called it canonical and it comes from the word canon which means:
a list or collection accepted as genuine
Websites could now state which page was the master content or which one is the original source. Search engines would focus on the preferred URL within their ranking your website for a keyword.
Recommended reading: Complete Guide to Technical SEO – Canonicalization
Common Issues Triggering Duplicate Content
As mentioned previously, there are many ways that could cause duplicate content to be triggered, such as the below:
- Like we displayed earlier with Spotlight, Google saw each variation of an eCommerce search page filter as unique.
- HTTP, HTTPS, WWW, non-WWW versions. Google will probably crawl and index all four versions. http://bikesabroad.com.au/ https://bikesabroad.com.au/ http://www.bikesabroad.com.au/ http://bikesabroad.com.au/
- Country/ Language versions of the same page. Example: www.yourdomain.com & www.yourdomain.com.au (this is a hreflang fix not a canonical fix – but still a common duplicate content issue)
- Having AMP and non-AMP versions of a page (e.g. https://example.com/page & https://amp.example/page)
- Pagination
If everything was lowercase that was fine. But make it uppercase or a mix and unique URLs multiply a hundred-fold. We'll look at how the canonical tag helps with SEO shortly but what does the code look like?
What Does a Canonical Tag Look Like?
The tag itself is a simple tag. It uses the rel attribute to define it, as in the example below:
Let's break that down into simple English.
Don't confuse this tag with the anchor link.
relates the current web page to an external resource. It's usually kept in thetag outside of the main body content. You may notice the same tag is used when adding a CSS stylesheet.
rel
The link tag adds an attribute called rel which stands for relationship. This can contain a range of values like stylesheet or icon.
In this case, the rel attribute is canonical. But it needs one other property to make it work correctly.
href
The hypertext reference or href is the website address you want to be indexed.
Later, we'll give tips on how to add these tags to your website. But there's one important fact to note:
Relationship Between Canonical Tags & SEO
If you read what Google says about canonical tags you'll discover the following advice:- Specify which URL you want in search results
- Consolidate links for similar or duplicate pages
- Simplify tracking metrics
- Manage syndicated content
- Avoid crawling time
We can see that Google uses canonical tags to identify what you want to be crawled and listed. Instead of opening an infinite number of options through database-created URLs, present the ones that make the most sense.
For example, choose https://www.yoursite.com/blue-products/ instead of https://www.yoursite.com/products.php?type=blue
This is good SEO practice anyway but combined with the canonical link it confirms to Google exactly what you want to rank.
Another benefit for using canonical tags when needed is that it merges duplicate pages together for Google to concentrate on. As a result, the spider will re-visit the ‘master’ page more frequently than the duplicate versions.
This is termed crawl budget and can impact very large sites. Google gives limited crawl budget time and resources so by feeding it duplicate content, new URLs get ignored.
By adding the canonical tag, Googlebot concentrates on what matters most.
When Should You Use Canonical Tags?
If you're unsure when and where to use this tag then examine the list below. If your URL relates to any of these issues then add a tag!
- Parameterized URLs – like search pages or session IDs e.g. yoursite.com/query=term or yoursite.com/sid=234
- Unique URLs for categories
- Default page names – e.g. yoursite.com vs yoursite.com/index.php
- Both secure and non-secure – i.e. HTTP and HTTPS
- Printable page versions – e.g. yoursite.com/page/print
- Subdomains – e.g. m.yoursite.com
- Both www and non-www
- Case sensitive URLs
- Trailing slashes – e.g. yoursite.com/blog/ vs yoursite.com/blog
Should you add a canonical tag on the same page as original content? Self-referencing tags sound silly but actually they're encouraged! Google says it's fine to add them to every page on your site. But try not to make any mistakes as confusion may result in wrong results.
Common Mistakes to Avoid When Implementing Canonical Tags
There are some golden rules when it comes to canonicalization and ignoring them could see Google ignore your hard work.
Don't Use Relative URLs
Relative URLs don’t include the full path to your page e.g. /blog/article-name.
This can be confusing to search engines so make sure everything’s absolute i.e. the full web address. Both work, however, but better to be safe than sorry.
Don't Pick the Wrong Domain Version
All websites should use a secure domain (https://yourdomain.com/page/) so make sure your tags include https://. Also, pick whether you want the www. prefix or not and stick with it.
Don't Use Uppercase or Mixed Case
Keep all your canonical URLs lowercase. Don’t mix it up to match your brand. Computers prefer file names etc. to be simple so that means everything’s the same.
Use only one canonical tag per page
Having multiple canonical tags on a page can confuse Google and they will probably both be ignored.
Don't point a canonical link to a 404 age
Setting a canonical link pointing towards a 404 page defies the whole person. Google bot will see the canonical tag and land on a 404 page, which will do more harm than good.
How to Implement Canonical Tags on Your Website?
What if your site has hundreds of pages? Do you need to manually check each one and add a canonical tag!?
Depending on your level of technical expertise, there are multiple ways of implemeneting the canonical tag.
1. HTML Tag
Probably one of the most easiest and quickest ways to add if you don’t have too many pages being flagged as duplicate. See the below example from Spotlight.
Head over the page that is being flagged as duplicate and then add the code in thesection of the page. Or download the Yoast SEO plugin and under the ‘advanced’ place the master URL in the ‘canonical URL’ box.
Image Credit: Yoast
2. HTTP Header (for PDF documents)
A PDF document doesn’t have asection like this blog would. So you would probably set your canonical to be something like the below.
HTTP/1.1 200 OK
Content-Type: application/pdf Link: <https://sh.chrdev.co/canonical-tag-guide-for-beginners/>; rel="canonical"
3. Using 301 Redirects
For automatically pointing your visitors to the master page, use a 301 redirect to specify canonical URLs.
However, it’s important to note here that only the canonical URL will exist and the other duplicated versions won’t. Use this when you have cases such as:
– WWW and non-WWW versions
– HTTP & HTTPs versions
How we can help?
Adding canonical tags helps Google decide what is a duplicate or spam content on your site, and most importantly, which URL you want Google to rank and focus on the most.
We hope this blog served as a user-friendly guide into the world of canonical tags and the benefits of having them implemented on your website.
StudioHawk is a dedicated SEO agency and is focused on driving sustainable results for our clients by optimising your website to rank well on Google.
Our simple pricing plan has no lock-in contracts. Contact us to discuss your requirements.

